|
基于以上定义,Hawkins进一步提出了最小FGD的计算方法,计算出NPAH中各句法位置上的名词短语在关系化时所必须处理的节点数。比如,如果最简单的关系从句用结构图(8)表示(根据Hawkins 2004:178上的7.10略做改动;其中每一短语中直接成分的语序未定;Ni表示关系从句中的中心名词,即关系结构中的填充词,在关系从句加工时需将其与关系小句中一个与其具有相同下标的次范畴指派词相连接),那么,各句法位置上的名词短语在关系化时所必须处理的节点数则如(9)所示(根据Hawkins 2004:179上的7.11略做改动;其中“RQ”表示“需要包括”,即 FGD 定义中的“扩展到”)。 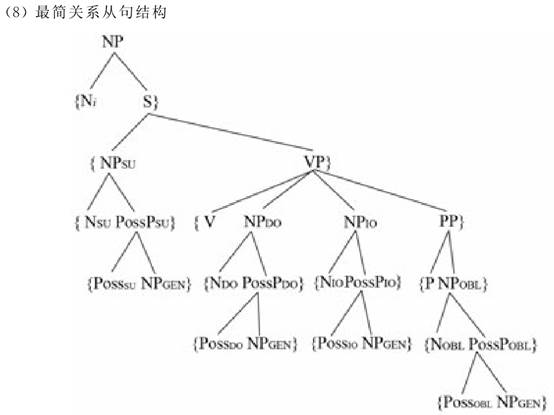   上面提到的(8)中“每一短语中直接成分的语序未定”这一点很重要,因为世界上不同语言的基本语序有很大差异。比如,就关系从句中的中心名词Ni与关系小句S的相对语序而言,英语是Ni在前,S在后,如(8)表面上显示的顺序那样;而汉语则刚好相反,是S在前,Ni在后。上述规定使(8)具有跨语言普遍性,即在(8)中,每一短语中直接成分的实际语序并未确定,视语言而异。 (9)中所列各最小FGD值反映了各句法位置上的名词短语在关系化时的处理复杂度:FGD值越大,说明处理复杂度越高,难度越大,可及性越低;FGD值越小,说明处理越容易,可及性越高。因此,根据上列最小FGD值,Hawkins(2004:177)将NPAH重新归纳如下: 这一排列顺序完全依据各句法位置上名词短语的最小FGD值的大小,最左边SU最小是5,以后依次递增,从而为Keenan&Comrie(1977)的NPAH提供了理论上的支撑。其中IO和OBL的最小FGD值相同,因而在Hawkins重新归纳的NPAH中合并在一起;OCOMP没有包括在内,因OCOMP在不同语言中的表达差异较大,Keenan和Comrie也没有为其提供系统的语料数据;GEN排在最后,因为GENSU,GENDO,GENIO,GENOBL的综合最小FGD值最大。 (责任编辑:admin) |