 表3中F、p和 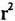 的数据,说明了在对语体差异的分析中,以上四个维度都是重要的、有意义的预测因子。F值和p值显示的是方差分析的结果,表明上述语体的平均维度分值在统计学上是否具有显著的差异。如果P值小于0.001,就说明我们观察到的语体差异几乎不可能是偶然发生的(不到千分之一)。 的数据,说明了在对语体差异的分析中,以上四个维度都是重要的、有意义的预测因子。F值和p值显示的是方差分析的结果,表明上述语体的平均维度分值在统计学上是否具有显著的差异。如果P值小于0.001,就说明我们观察到的语体差异几乎不可能是偶然发生的(不到千分之一)。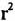 值表示语体差异的强度和重要性,它测量的是维度分值中方差的百分比,而维度分值是可以通过语体类别来预测的。例如,维度1的 值表示语体差异的强度和重要性,它测量的是维度分值中方差的百分比,而维度分值是可以通过语体类别来预测的。例如,维度1的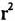 值说明90.7%的变异都可以通过每个语篇的语体类别来解释。这个数据表明维度1对语体差异的研究是有意义的,它是一个极其重要的预测因子。 值说明90.7%的变异都可以通过每个语篇的语体类别来解释。这个数据表明维度1对语体差异的研究是有意义的,它是一个极其重要的预测因子。多维度分析的最后一步是从功能的角度来解释每个维度。与单个的语言特征相类似,语言特征的共现模式也是功能性的。也就是说,语篇中共现的语言特征与它们所共有的交际功能相对应。我们主要根据以下两点来解释维度:一是共现的语言特征所共有的交际功能,二是该维度下语体的异同。表2已列出本项研究中四个维度的功能标记: 维度1:口头话语与书面话语 维度2:程式化的话语与以内容为中心的话语 维度3:对事件的重构 维度4:以教师为中心的立场 下面我们将对语体变异模式进行多维度描写,讨论每个维度内共现的语言特征集合以及美国高校校园语体的分布,并进一步考察这些特征在特定语篇中的功能。这些语体分别是:①服务接待时的会话;②办公时间的会话;③实验室中的会话;④学习小组讨论话语;⑤课堂教学管理话语;⑥课堂教学话语;⑦课程管理话语;⑧教科书;⑨课程资料;⑩机构话语。根据维度1,①-⑥为口语体,⑦-⑩为书面语体,表4同时呈现了它们在四个维度中的平均分值: 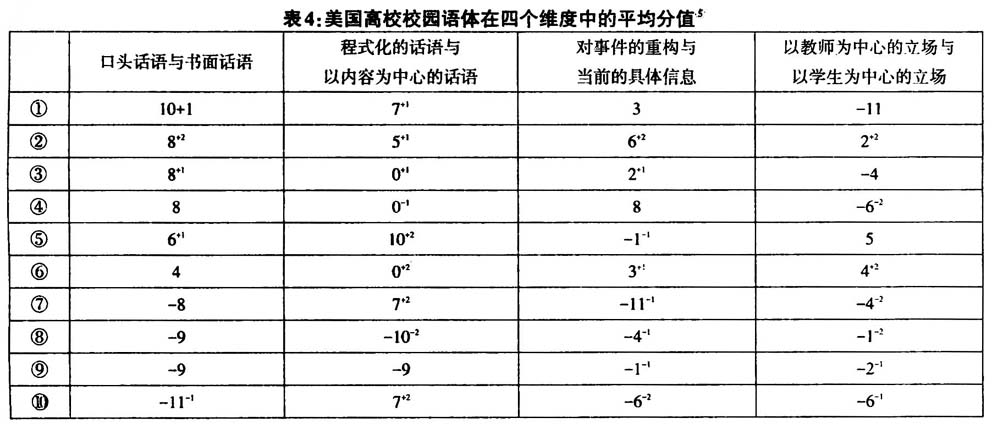 (责任编辑:admin)
(责任编辑:admin) |