|
从图6可见,a-d的分组态势相同,或者说聚类树的结构相同,但相似度值有明显的差异(取值范围分别为0.30-1、0.48-1、0.65-1、0.37-1)。而e的分组态势则自成一路(聚类树的结构不同)。这里有两点值得注意:(1)虽然图6a-e的分组态势或相似度值有差异,可是小组的个数(4个)及其内部成员都完全相同。换言之,聚类虽然存在着不同的方法,可是其出发点(小组)都是相同的,差别在于如何归并出更大的组并计算出它们的相似度值。(2)聚类分析在处理定性数据时往往既重性质(1或0)也重管辖范围。例如梅县和厦门等四地,如忽略1的具体辖字,表现可谓完全相同,都是011、16、92,可是5种聚类都没有将梅县和厦门等四地归为一组,可见只要方法合适,聚类分析对辖字的不同有足够的敏感性。 3.3 不同软件对同一数据进行聚类分析的结果。这里采用的是IBM SPSS Statistics V20。SPSS的系统聚类(Hierarchical Cluster Analysis)提供了7种方法,同时还有度量标准(Measure)的选择。本文仅选最远邻法(Furthest neighbor,相当于NTSYS的COMPLETE法)和最近邻法(Nearest neighbor,相当于NTSYS的SINGLE法),度量标准为“二分类-简单匹配”(Binary-Simple matching)。结果见图7。 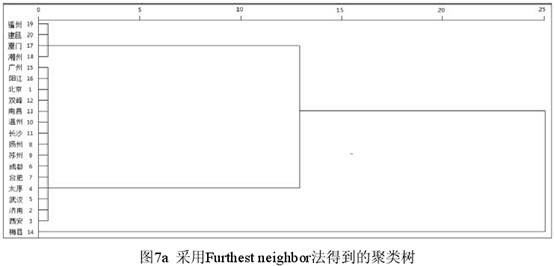  从图7可见,SPSS的聚类树图不仅表述方式跟NTSYS很不一样,聚类的结果也有明显的差异。不仅树的结构不同,小组数也不同,图7只分3个小组,图6分开的北京等5个方言和武汉等10个方言SPSS合为了一组。NTSYS分开北京组和武汉组的原因是“芒”字前者取值为0而后者取值为9。造成这种差异的原因在于NTSYS和SPSS对数据缺失的态度不同。如果以表3的“芒、莣、铓”3字(含人造数据)为依据进行聚类,对SPSS来说,无论数据缺失以不输入任何数字表示还是以9表示,都会发出如下警告:“没有足够的案例或变量,无法计算近似值度量。无法计算距离。”因为SPSS将前者视为缺失,将后者视为越界,都予以忽略。而NTSYS则可以根据同样的数据(缺失以9表示)进行聚类,结果见图8。 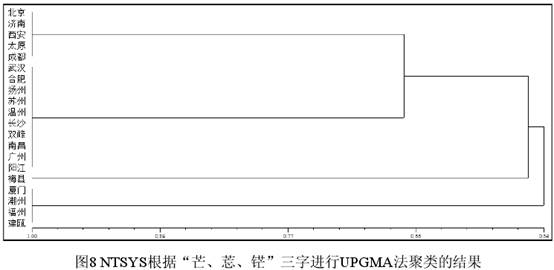 图8的聚类树结构跟图6a-d相同,只是相似度值不同。可见,虽然都是用表3的数据进行聚类,但是图6(NTSYS)和图7(SPSS)处理的数据范围是有差异的,SPSS实际上排除了表3所有含缺失值的变量行(即“芒、莣、铓”3字)。假设NTSY也排除“芒、莣、铓”3字,根据我们的检验(为节省篇幅省略聚类图),SINGLE法的结果和SPSS最近邻法的结果差别不大(即3个小组在同一刻度上联接),COMPLETE法则仍跟图6d接近(但只有3个小组,北京至阳江15个方言不分组),而跟SPSS最远邻法的结果(图7a)不同,梅县和厦门等4个方言的地位正好是相反的。可见使用不同的软件有时也会得到不同的结果。方言研究中常常需要面对含缺失值的数据(即不能完全对齐的语料),对二值分类的数据而言,采用NTSYS一类的软件进行聚类分析显然更为灵活周遍。 图6a-c大同小异,似乎选什么系数都无关紧要,但事实并非如此。以SPSS的最近邻法为例,如果选择“二分类-尺度差分”(Binary-Size difference),结果就跟图7b不同,见图9。  图9和图7b的差别在于梅县和厦门等4个方言同为一个组。 (责任编辑:admin) |