|
三 不同聚类的对比 3.1 数据的改造及新数据的手工分类。为了做进一步的实验观察,现在把表1厦门、潮州、福州、建瓯的“方、芳、防、亡、望”5个字的数据改为1,潮州、福州、建瓯的“铓”字的数据改为1,其他数据不变,从而形成一个包含了部分人造数据的新表,下文一律称为表3(为节省篇幅略而不列)。表3的特点在于客家话(梅县)和闽语(厦门、潮州、福州、建瓯)除“坊、仿~效、妨、纺、仿相似、访”(都是0)、“芒”(都是9)表现相同外,有6个字为1,1个字为9,但是辖字不同,呈互补关系。根据表3的数据,最自然的手工分类方案如图5所示(已将相似度的刻画考虑在内)。 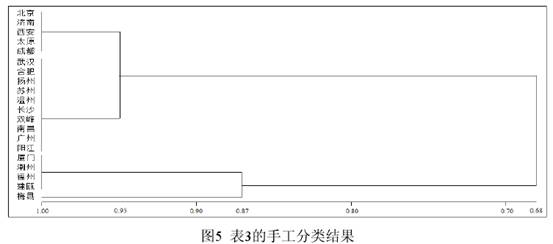 图5显示,根据表3的数据最自然的手工分类结果是,梅县和厦门、潮州、福州、建瓯在一个大组(A组)里,其他方言在另一个大组(B组)里。A组下分为两个小组,梅县自成一组(A1组),其余4个方言组成另一个组(A2组)。B组也下分为两个小组,北京、济南、西安、太原、成都为一个组(B1组),武汉等其他10个方言为另一个组(B2组)。A、B两个大组的相似度值为0.68(13/19),因为A、B2有13个字的表现相同。A1、A2的相似度值为0.87(7个字的表现相同,其相似度值为0.37[7/19]+显著的1表现0.5[主观取值])。B1、B2实际上只有1个字的差别(芒),其相似度值定为0.95(18/19)。图5的重点在于根据有无1的表现把20个方言点分为了A、B两组,至于A1、A2的相似度如何取值,自然可以因人而异。 3.2 不同聚类方法形成的分析结果。计算相似性矩阵可以采用不同的系数,而聚类的方法也有很多种。NTSYS提供了16种系数和8种聚类方法。不同的系数在针对性和计算时间上都可能存在差异,甚至对数据的类型也可能有不同的要求。例如J系数(即Jaccard 系数)对表3的数据会给出错误提示而拒绝进行计算,因为其中包含了缺失值9。下面只选取5种计算结果来做比较,每种结果都标明所用系数和方法。H指Hamann系数,RT指Rogers & Tanimoto 系数。COMPLETE指完整联接法(又称全联接法、最远邻法),SINGLE指单联接法(又称最近邻法)。SM和UPGMA已见前文。计算的数据都是表3。 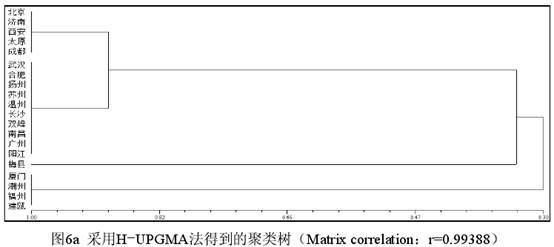 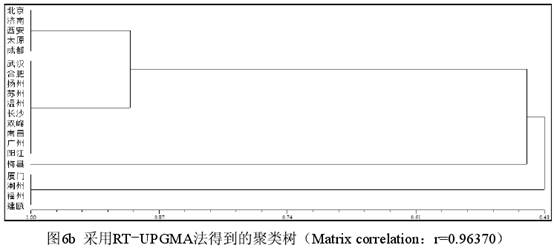 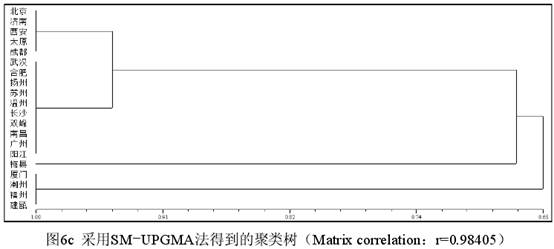 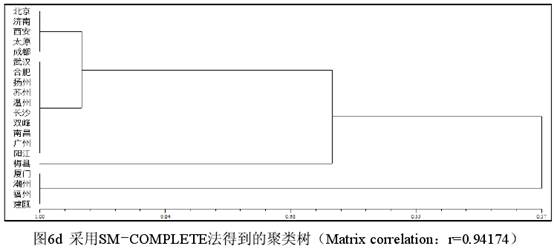 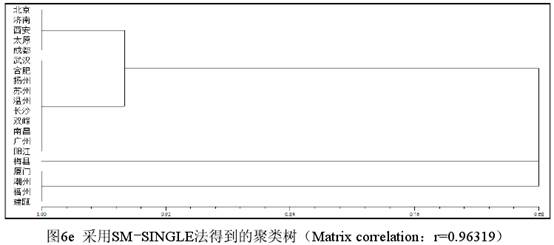 (责任编辑:admin)
(责任编辑:admin) |