|
2.2 古宕摄合口三等非组字今读的韵母特征相似性矩阵。特征矩阵建好后用NTSYS的相似性(Similarity)模块中的定性数据(qualitative data)即可计算出其相似性矩阵(本文不加说明时一律采用SM系数,即简单匹配系数[Simple Matching Coefficient]),以北京、长沙、厦门、梅县为例:  得到相似性矩阵后,就可以用NTSYS聚类(C-lustering)模块中的SAHN(Sequential、Agglomerative、Hierarchical and Nested Clustering Methods,时序、集群、层次和嵌套聚类方法)进行聚类计算,求出聚类树矩阵。本文采用UPGMA(unweighted pair-group method with arithmetic means,非加权组平均联接法)进行计算。得到的结果文件用NTSYS制图(Graphics)模块中的树图(Tree plot)进行计算即可得到如图2所示的聚类树图。 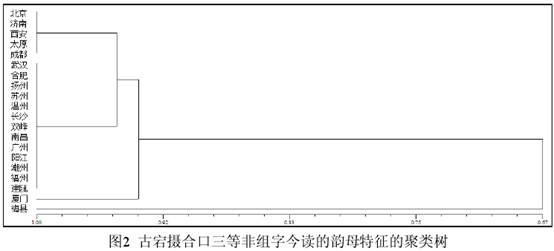 为了检验上述聚类分析结果的好坏,还需要进行比较分析。即首先用 NTSYS 聚类(Clustering)模块中的系数值(cophenetic values)求出聚类树矩阵的同象值,然后再用制图(Graphics)模块中的矩阵比较图(Matrix comparison plot)导入相似性矩阵文件和同象值文件并加以比较计算。本文略去比较图,仅列出矩阵相关性系数如下: 矩阵相关性系数的值越大,说明聚类树矩阵对相似性矩阵的偏离度越小,即失真度越小。 2.3 古宕摄合口三等非组字今读的韵母特征的聚类树分析。图2的聚类结果并不复杂,共两个大组,梅县为一个大组(A组),其他19个方言为一个大组(B组);B组又下分为两个小组,厦门为一个小组(B1组),其他18个方言为一个小组(B2组);B2小组再下分为两个小小组,北京、济南、西安、太原、成都为一个小小组(B2a组),武汉等其他13个方言为一个小小组(B2b组) B2a、B2b两个小小组内的方言相似度值均为1,即没有差异;B2a、B2b的相似度值约为0.95,差别是“芒”是否来自武方切。B1、B2两个小组的相似度值约为0.935,主要差别是是否用“铓”。A、B两个大组的相似度值约为0.67,主要差别是“放、房、缚、莣、网、忘”的韵母是否读-i-。 显而易见,聚类树主要是建立在数量关系之上的,因此聚类分析的结果并不能作为分类的唯一方案。如果由手工来对表1进行分类,实际上有两个方案。一个方案跟图2相同,立足于定量分析,而另一个方案则立足于定性分析,即按照有无-i-的读法,首先把厦门、梅县分在一个大组里,然后再下分厦门、梅县两个小组;其他方言为一个大组,再下分北京等和成都等两个小组。当然就表1而言,把厦门、梅县分在一个大组里的做法并不可取。厦门虽然有1的表现,可是“铓”字在厦门和梅县不能对齐,在闽语内部也缺乏普遍性,因此忽略这种偶发特征、不把厦门跟梅县联系在一起大致是合理的。 B组下的3个小组相似度均在0.93以上,属于高度接近,因此对其分组其实并无太大意义。现在的问题是:A、B两个大组的相似度达到了0.67,分组是否有意义?回答显然应当是肯定的。首先,A、B两个大组的相似度值(0.67)和B组下3个小组的相似度值(0.935)之间存在着显著的落差(0.265);其次,造成A、B两个大组的相似度值较大的原因是存在着11个梅县和其他19个方言取值都为0的字,即“方、坊、芳、妨、防、仿~效、纺、仿相似、访、亡、望”,这些字约占古宕摄合口三等非组字总字数的58%。如果排除这11个没有差异的字,结果会很不相同。情况如图3所示(Matrix correlation:r=0.99388)。 (责任编辑:admin) |