|
4.4 资源库的索引结构 我们根据资源库的特点设计了双重索引,分别以话题大类和场景作为根目录,前者作为主要索引,后者作为辅助索引。以话题大类为根目录的索引结构为“话题大类-话题-子话题-场景”;以场景为根目录的索引结构为“场景-话题大类-话题-子话题”。示例如下: 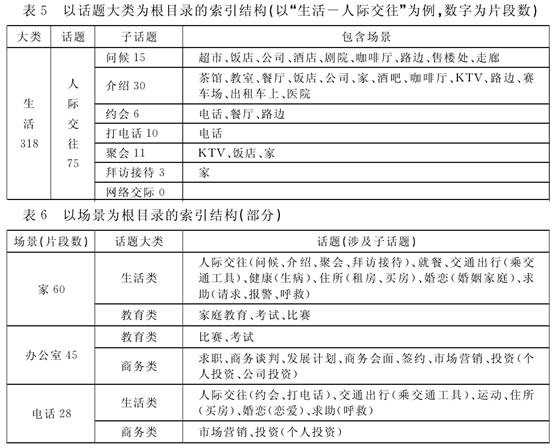 五 影视片段和话题的相关度排序 影视片段相关度是指该影视片段与其所属话题的关联程度,即该影视片段对于这个话题来说是否具有代表性。我们主要从两方面来衡量影视片段的相关度:用词用语、交际场景。 5.1 用词用语 5.1.1 基本原理 我们可以通过对每个语料片段中语言的分析来考察语料片段的相关度,比如使用的词语和短语等。词语和话题之间的联系是十分密切的,每个话题下都有一些使用度比较高的词语,在看到一些常用的词语或句式时,我们也往往会联想到某个话题,例如“介绍”、“这(位)是……”、“幸会”、“很高兴认识你”会让我们想到“介绍”这个话题,“……多少钱?”、“我要……”会让我们想到“购物”或“就餐”的话题。以下两个片段都是关于话题“介绍”的: 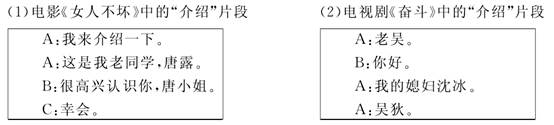 同样都是四句话,第一个片段出现了词语“幸会”、“这是 ……”、“介绍”、“很高兴认识你”,第二个片段也是介绍,但是比较含蓄,因此第一个片段较第二个片段而言与“介绍”话题的相关度更高。 5.1.2算法实现 话题词表是将能代表该话题内容特征的词语聚集在一起形成的词表。基于分话题的汉语教材会话语料库(来自35本教材),我们已经利用文本分类中特征提取的方法和专家人工干预的方式,进行话题库的词语聚类(刘华、吕荣兰,2013),每个话题都聚类出一个代表其质心特征的词表(类特征向量)。例如“介绍”的话题词表如下: 介绍(2.7457)、幸会(2.7166)、荣幸(2.6897)、久仰(2.6862)、认识(2.6593)、见到(2.6035)、高兴(2.5848)、欢迎(2.5568)、叫(2.5427)、姓(2.5264)、贵姓(2.5213)、你好(0.5621)…… 其中每个词语对于“介绍”的贡献还不一样,词语后括号内的数字就是每个词语的贡献权重。 (责任编辑:admin) |