|
四 汉字习得情况分析 4.1 数据分析 数据库中的每一个汉字,除第二、三部分提到的各种得分情况外,我们还可以标注出多种属性。其中第一大类是汉字的普遍属性,包括拼音、声调、笔画数、自然字频、是否左右对称、结构方式、造字方式、汉字等级等多项。第二大类是与受试实际参与的教学过程有关的汉字属性,包括课号(作为连续变量,可表示该汉字出现时所处的学习阶段)、全书字频、生词总表字频(可以代表该字在全书中的构词能力)以及该字所在课的新出汉字总数(第二部分已统计)。 我们首先利用得分和课号都是连续变量的特性来检验第三部分的一些数据结果。分别对《博雅》全部1045字的课号—认读得分、课号—书写得分、课号—无法认读数、课号—错误认读数、课号—空字数、课号—错字数、课号—别字数进行二变量相关分析,结果如表4所示,与第三部分的发现一致的是,单个汉字的认读和书写得分(0-30之间)随出现时间的推移都呈明显的下降。与之相应,无法认读数、错误认读数和无法书写(空字)数(0-30之间)随时间推移都显著上升。比第三部分显示得更清晰的一点是错误书写数随时间的推进出现明显的下降。别字数与该字在教学中出现的早晚没有关联。这些数字再次支持我们在3.2部分提出的中介状态“连续统”观点。 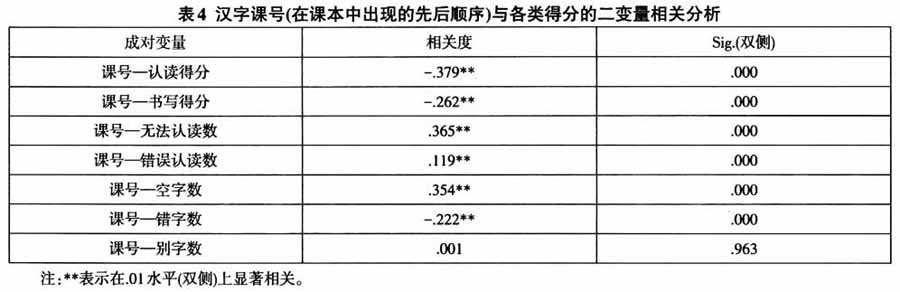  回头来看汉字的整体得分情况。全体1045汉字的平均认读/书写得分及标准差情况如表5所示。对于这些汉字,若仅依靠直接观察的方法,我们也能发现一些共同的特征。比如,得分最高的汉字不仅普遍笔画数较少,结构简单,而且似乎使用的频率都很高。无法认读数高的汉字和无法书写数高的汉字有一部分是重合的,它们都具有笔画数多、结构较为复杂的特点。错误认读数高的汉字多数在去除、加上或者改动某一部首的情况下能写成另一汉字(如“捎、稍、销”三字),而错字数高的汉字似乎都是左右不对称的。别字数高的汉字似乎都在音或形的一个方面能找到相近的其他字。然而,我们有理由怀疑诸如“频率、出现先后”这样的因素会导致这些错误的产生,因此,有必要引入更全面的方差分析和回归分析来一窥其真相。 在数据库中,可作为因变量进行研究的数据项有8项,分别为:无法认读数、认读错误数、认读得分、错字数、别字数、无法书写数、书写得分以及习得总分(=认读得分+书写得分)。除最后一项的数值范围为0-60以外,其余皆为0-30。 作为自变量引入的数据项分3类,其一是分类变量,我们设计的有是否左右对称②、汉字的结构方式③(但在实际统计中,发现“框架”结构的字数仅5字,为了统计方便我们将其归入“独体”结构)、造字方式(钱乃荣主编(1990)划分的独体、义符+义符、义符+音符、音符+记号、义符+记号、记号+记号6大类的划分较为科学,在此采用之)3种。 其二是等秩变量1种,即旧版HSK大纲所规定的甲乙丙丁4级汉字,与超纲字合在一起后,标记为1-5共5个等级。 (责任编辑:admin) |