语言的谱系分类和类型学分类
http://www.newdu.com 2025/12/16 01:12:24 《现代外语》2020年第3期 吴建明 参加讨论
摘 要:分类是一个研究领域的基础。对世界语言进行有效的分类,可以揭示它们之间的相似性和差异性,进而发现语言现象的本质。当前语言学研究存在两个基本的分类体系:谱系分类和类型学分类。谱系分类根据语言间的直接演变关系和亲缘关系划定语系、语族、语支以及语言和方言;类型学分类根据语言中存在的不同形式和功能,形成比较概念、描写范畴以及相应的概念结构。谱系分类把历时和共时上共享某些特征或属性的语言归类,而类型学分类则把语言中存在的不同特征或属性进行归类。本文对这两个分类体系的主要方法、相互关联以及共同存在的问题进行讨论,并在此背景下探讨汉语和其他语言在音系、形态、句法、词汇等方面的演化和分布特征。 关键词:谱系;类型学;汉语;语系;比较 作者简介: 吴建明,上海市上海外国语大学语言研究院。 1. 引言 范畴化是人类认识世界的基本方法,用于对客观事物或抽象思想的区分、理解和辨认。语言学分类也是一种范畴化。世界上有成千上万种语言,不同语言又拥有各式各样的特征属性,语言学家需要提供一个科学合理的分类体系,才能了解、把握和深入研究各个不同的语言。 谱系分类(genealogical classification)和类型学分类(typological classification)是当前语言学界最为普遍的两种分类法。前者把一组具有亲缘关系的语言,根据它们的直系传承和分支演化关系,进行分类;后者把语言的种种属性,根据它们的形态、音系、句法以及语义语用特征,进行分类。语言学的这两种分类方法受到人口、地理、历史、社会等因素的影响,特别是语言地理区域、语言和方言、多源发生(polygenesis)、混合特性等均会给这两种分类体系带来一定的困难。 本文主要讨论谱系分类和类型学分类,涉及各自的基本概念、研究方法以及相关问题,并对不同语系的相关实例和新近研究成果进行讨论。 2. 语言的谱系分类 语言的谱系分类受到了生物学分类方法的启发。生物学家对自然生物进行分类,目的在于弄清不同物种之间的亲缘关系和进化关系。直进演化(anagenesis/vertical speciation)和分支演化(cladogenesis/horizontal speciation)是物种演化的两个基本形式。直进演化是指一个物种在漫长的历史进程中,由量变到质变,直至成为新物种的过程,是一种垂直演变或直系传承关系;分支演化是指一个物种分裂为不同类群,每个类群又演变出新物种的过程,是一种水平演变关系。直进演化和分支演化共同构成了生物学意义上的进化树(phylogenetic tree)。 借助生物学物种起源的思想,语言学家通常假定一组具有亲缘关系的语言存在一个共同的原始语(用*表示),并且原始语也通过直进演化和分支演化两种方式,形成当前的谱系分支体系。在这个过程中,历史语言学家需要寻找一组语言的共同源头,称为“历史重构”(historical reconstruction);同时,也要为某些具有共同特征的亲属关系语言建立子群,形成语族、语支、语言或方言等概念,称为语系内部的“次分组/分群”(subgrouping)。 语言的直系传承关系一般分为上古(old/archaic)、中古(middle)和现代(modern)三个历史阶段,如下图1。图1中,汉语、英语和波斯语分别从早期的语言一脉相承演化而来。这种表示语言间直系传承的演变关系,且不包含旁系分支的情况,语言学上也称直进演化。其中,上古汉语和中古汉语分界线大致发生在胡汉融合的南北朝时期(公元420-598);古英语和中古英语的分界线大致发生在诺曼征服时期(在11世纪晚期);古波斯语和中古波斯语的分界线大致始于阿契美尼德王朝(公元前550-330年)后期。这三个历史阶段的划分一般以各自语言史上的重大事件及其所带来的语言变革为主要依据(如王朝更迭、外族迁入等因素)。 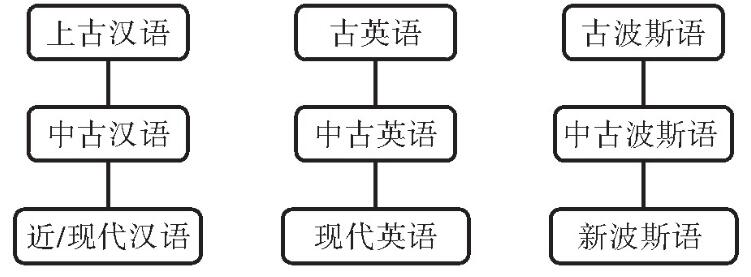 图1 汉语、英语和波斯语的直进演化关系 谱系分类的另外一个方式是分支演化。原始印欧语分支出原始日耳曼语后,内部再分裂出北、西、东三个语支,其中英语、德语、荷兰语等属于西日耳曼语支。原始汉藏语分裂出原始汉语、原始藏缅语、原始壮侗语等支系后,各个支系又进一步分化,汉语内部在不同历史阶段分支出官话、晋、赣、湘、吴、闽、客、粤等方言。如下图2: 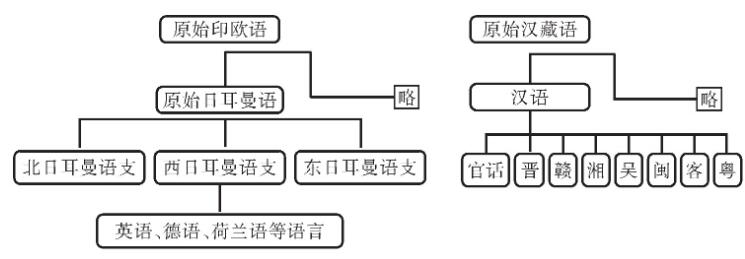 图2 日耳曼语族和汉语族的部分分支关系 在漫长的语言演变过程中,早期语言形式很难被完整地保存记录下来。语言学家只能靠“比较法”(the Comparative Method)(Campbell 2013),重新构拟原始语言的面貌。比较法认为跨语言上符号和意义的对应是任意的,也正是由于这种任意性,当两个或多个语言在一定规模上出现相互对应的语音、语法模式时,就有可能进一步推断它们之间的某种亲缘关系。例如,古日耳曼语和古印欧语之间存在一系列系统性的音变规律:古印欧语的清塞音和浊塞音在古日耳曼语中分别有规则地发成清擦音和清塞音(圆唇软腭浊送气塞音,如/ɡwʰ/还可能变成/ɡw/,后来又进一步擦音化,变成了/w/或/v/的音位变体),如(1):  古日耳曼语相对于古印欧语的系统性音变是一组语言内部的共同的变革,称为“共同创新”(shared innovation)。与之类似,在汉语族内部,中古汉语的浊塞音和擦音,如/b/,/d/,/ɡ/,/z/,/v/,在当前官话区发生系统性的清音化,也是一种共同创新。然而,吴方言区依然不同程度地保留中古时期的浊音声母。大多数学者认为这是一种“共同保留/存古”(shared retention),即直系传承关系的语言之间继承了先前语言的种种特征,没有变革发生,如(2):  保留和创新是历史重构和分支演化的重要证据。在汉语族内部,中古汉语存在塞音声母三分的现象,如/p; 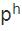 ;b/(Bang帮;Pang旁;Bing并)或/t; ;b/(Bang帮;Pang旁;Bing并)或/t;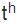 ;d/(Duang端;Tou透;Ding定)。除了上述的吴方言存留浊音声母外,赣语、闽语、湘语以及其它一些汉语方言均不同程度保留了浊声母,从而可以推断这种源自共同祖先语言的特征。与之不同,法语的feu和英语的fire“火”虽然都是擦音声母/f/,但二者是罗曼语族和日耳曼语族各自创新的结果。其中,法语的/f/来自原始印欧语送气浊塞音/* ;d/(Duang端;Tou透;Ding定)。除了上述的吴方言存留浊音声母外,赣语、闽语、湘语以及其它一些汉语方言均不同程度保留了浊声母,从而可以推断这种源自共同祖先语言的特征。与之不同,法语的feu和英语的fire“火”虽然都是擦音声母/f/,但二者是罗曼语族和日耳曼语族各自创新的结果。其中,法语的/f/来自原始印欧语送气浊塞音/*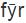 <原始日耳曼语*fūr<原始印欧语*pūr)。可见,feu和fire并不是同源词,不能构成语言次分组的证据。同理,上古汉语和上古英语都存在介音/*r/,也都发生部分/r/脱落或转化为/l;i/(如古英语spræc>现代英语speech)。由于英语和汉语分属不同语系,在至少1万年的区间内各自源头不同,因此这种相似了音变规律并不构成谱系分类证据。 <原始日耳曼语*fūr<原始印欧语*pūr)。可见,feu和fire并不是同源词,不能构成语言次分组的证据。同理,上古汉语和上古英语都存在介音/*r/,也都发生部分/r/脱落或转化为/l;i/(如古英语spræc>现代英语speech)。由于英语和汉语分属不同语系,在至少1万年的区间内各自源头不同,因此这种相似了音变规律并不构成谱系分类证据。在上述比较法中,研究对象主要是核心词,通常指的是那些简单常用,不太可能借用的词汇,如英语I、you、we、this、that、who、what、dog、bird、tree等(但不包括一些拟声词特征的词汇,如mum、papa等)。Swadesh(1950)认为核心词汇的演变速度是恒定的,在1000年的区间里,英语等语言核心词汇的保留率是0.85,并随时间推移逐步递减,由此通过较为简单的公式推算某个祖先语言起源或姐妹语言分化的时间点。然而,受人口、地理、接触等因素的影响,语言学家发现各个语言中核心词汇的保留率并不都和英语一样,而且即使是同一语言内部,其核心词的演变速度也不一致。因此,目前语言学家寻求新的计算方法和新的研究对象来探索谱系分类问题。比如,采用广义线性模型、人口规模与语言演变模型以及系统发生学方法等。系统发生学的方法直接量化语言由于直系传承(或直进演化)而导致的相似性,绕过因语言接触而带来的借词干扰,目前较受关注。据最新系统发生学研究,Sagart et al.(2019)考察了50种古代和现代汉藏语,得出原始汉藏语起源于7200年前的中国北方种植粟的农业先民之中;张梦翰等同样利用系统发生学的方法,结合遗传学、考古学等证据,得出汉语在汉藏语系中分支出去的时间可追溯到5900年前的黄河流域(Zhang et al.2019)。 语言的谱系分类是个体语言描写和跨语言比较的重要依据,为语言历时演变、语言接触以及语言形式功能的分布等提供重要的支持。由于当前的谱系分类主要依靠核心词的音变对应规律来分析和计算,一些语言学家也尝试使用某些稳定的类型学特征进行谱系分类。下文将对这些问题进行讨论。 3. 语言的类型学分类 与谱系分类不同,语言类型学主要关注世界语言中纷繁复杂的形式结构及其功能,并对其中的形态、句法、音系以及语义语用等特征进行分类和细化。举例来说,音系类型学家发现所有语言都区分高低元音,并且元音的高低通常比元音的前后或圆唇不圆唇,处于更优先的地位。据此,我们可以预测在具有“元音和谐”特性的语言中,至少先有元音高低和谐,再有其他类型的元音和谐。比如,在楚科奇语中,名词kure“网”和动词na“撒”合并为一个短语(称“名词并入”)并充当谓语成分时,必须与动词一起参与短语的内部“低元音和谐”,即kure→kopra。再如,就音节结构而言,类型学认为音素在音节中的排序至少要符合“响度等级序列”,体现在音节内部,韵核响度最高并由此向两边递减。如(3):  响度等级序列作为一种音系类型学的共性,解释了世界语言的音节为什么倾向于CV结构,而不是VC结构,也解释了复辅音声母(如/kl/、/nl/、/ks/等)和复辅音韵尾(如/lk/、/ln/、/sk/等)等带有普遍性的辅音序列。比如,Karlgren(高本汉)(1954:280)为汉字“欄”构拟的上古汉语复辅音为/kl/,就符合这个序列的预测。此外,类型学家还发现一些复杂的辅音,如吸着音/搭嘴音、喉化辅音、边擦音、塞擦音、小舌音、喉壁音、齿/齿龈无咝擦音等,只能在大(>34)或较大规模(23~33)的辅音库藏中才会出现。类型学上称之为“规模原则”。类型学的这些带有普遍共性性质的发现有助于谱系分类研究,至少在进行古音构拟时,历史语言学家要考虑或满足人类语言倾向性或可能的音系规律。 语言类型学对形式和功能进行分类时,需要区分“比较概念”和“描写范畴”(Haspelmath 2010)。比较概念是一种跨语言的特性,也是一种比较基准,仅仅服务于跨语言比较以及相关的数据库构建;描写范畴则是适合个体语言特有的语法体系的术语,是个体语言内部形式和功能的一致性的体现。举例来说,基本语序是类型学最重要的研究对象之一,涉及主语(S)、宾语(O)、(谓语)动词(V)三个比较概念。在具体语言中,主语或宾语有时需要功能性定义(如话题性或施事角色);有时需要形式定义(如控制项或一致关系标记),但在跨语言层面上,类型学指的是在中性独立文体中,陈述性小句的名词性短语参与者,其中主语是有定、指人的施事,宾语是有定的受事,谓语动词是表动作(非表状态或事件)的动词。从跨语言的角度,当个体语言内部S、V和O的功能和形式无标记地满足上述定义,也具备跨语言上较高的可复现率时,我们就可以进行更高层级的归纳,把某个语言称为SVO型、SOV型或SVO和SOV混合型语言(金立鑫2019),但这些定义仅为跨语言比较基准服务,个体语言不一定要按比较概念来定义主语或宾语,有时需定义适合自身的描写范畴。 基本语序是语言最重要的类型学属性,S、V和O的相对位置也间接决定了其他成分的相对语序。类型学认为句子成分的线性排列主要是为了使各个语言获得便捷、高效的语言处理效率,由此各自形成相对固定(或语法化)的语序类型。比如,大多数语言采用主语居首的基本语序,目前可验证的分布频率排序如下:SOV>SVO>VSO>VOS>OVS>OSV。此外,无论是VO语言还是OV语言,V和N(O)靠近时,都有利于尽早地进行成分识别。因此,下面两种语序被认为是最合适的语序匹配,如(4): (4)a.VO---V+[N+Rel](关系小句在名词之后) b.OV---[Rel+N]+V(关系小句在名词之前) 以英语为例,英语是VO型语言,关系小句相应匹配在名词之后,如(5)a;与之不同,日语是OV型,也称动词居末型语言。听者一般把句末动词作为核心,从右到左,进行成分识别,因此关系小句在名词前。换句话说,在没有类似汉语关系小句标记“的”的情况下,日语的基本语序特征有助于读者对主从句的消歧,如(5)b;由于汉语在历史上与蒙古、通古斯地区等地区的OV型语言频繁接触,这很可能导致当前SVO和SOV两种语序的混合,并存在关系小句在名词之前的特征,如(5)c。 (5)a.The policeman caught the thief who stole the car.(英语)  “警察抓住了偷车的小偷”(日语) c.警察抓住了偷车的贼。(汉语) 当前,类型学界广泛使用语言数据库进行各项相关性研究。《世界语言结构地图集》(The World Atlas of Language Structures,简称WALS)是类型学界最为著名的数据库,涉及上百个用于跨语言研究的比较概念。类型学家至少从中可以获得三类共性表述:第一,没有例外或反例的“绝对共性”;第二,体现语言主体倾向或趋势的“倾向性共性”或“统计共性”;第三,带有相关性预测要求的“蕴涵共性”。 语言类型学还涉及对语言概念结构的分类。语义地图就是一种典型的概念结构。根据家族相似性原理,语义地图把语言中某些特定的表达式及其意义或功能,根据它们之间一系列的相似关系,绘制在几何地图上,并以各种可视化的方式显示出来。比如,跨语言上充当谓语的形容词的存在以下语义地图: 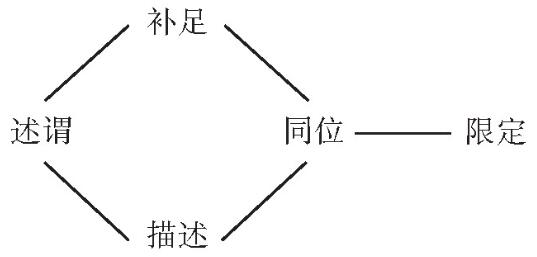 图3 谓语形容词的语义地图 上述语义地图反映了跨语言上形容词在形式结构之间的相似性或差异性,从中也能获得蕴涵关系的解读。比如,英语形容词在表达上述任何一个功能时,也用同一形式上表达其它功能,如(8): (6)a.John ate the meat raw.(形容词充当次级谓语描述成分) “约翰生吃肉。” b.The happy boy went to the party.(形容词充当限定/修饰成分) “那个快乐(的)男孩去了派对。” c.John,happy as always,went home.(形容词充当同位成分) “约翰,快乐如常,回家去了。” d.I consider John intelligent(形容词充当补足语成分) “我觉得约翰聪明。” 从上面的汉语翻译可以看出,汉语在补足、同位、限定三个连续区间采用的形式是一样的,但却很难像英语一样,充当次级谓语的描述成分。事实上,英语在处理次级谓语时需要区分“以名词性参与者为导向”和“以整体事件为导向”两种情况,后者采用副词性状语成分。比如,John left the party angry vs.John left the party angrily。在(5)a中,虽然英语raw是以名词性参与者meat为导向,因而是形容词性的,但汉语却习惯处理为事件为导向的副词性状语。这是因为汉语存在动词前的(方式)状语充当无标记焦点的倾向或手段,而英语一般把句子末尾的成分作为信息焦点。因此,“生吃肉”是语义和语用双重符合的最佳翻译,而“约翰吃生肉”,虽然语义上正确,但忽略了英语的焦点信息,因而不是合适的翻译。 语义地图既是一种概念结构,也是一种描写工具,它有助于发现语言间不对等、不对应的现象,也提供了语言差异、语言变异的模型,从中也能获得语言历时演变的证据(除了语义地图外,作为一种探索,作者提出个体语言“库藏结构”的概念(Wu 2019),指的是个体语言基于某个核心意义的形式和功能可以用类似决策树或分类树的方法表达出来,并认为库藏结构也具有跨语言可比性)。 4. 谱系分类和类型学分类的共同问题 谱系分类和类型学分类都面临一些需要解决的问题,如多源发生、语言和方言认定、证据选取等。 4.1 单源说和多源说 历史语言学家建立一组语言的谱系树,其隐含的预设是这组语言存在一个共同的祖先语言,但这个语言仅仅是某个语系的共同原始语,并不能成为其他语系语言的原始语。换句话说,由于我们获得历史语言学证据的基本上限是1万年左右,语系是当前语言最大的族群单位,在语系之外没有可以证明语言间的亲缘关系的证据。 然而,人类的语言至少存在了5万年以上,因此我们也没有直接证据证明或否认不同语系是否源自一个共同的祖先语言。因此,一些语言学家采用语群(phylum)的概念,代表比语系更为松散的语言族群,如亚非语群(也称为亚非语系)(Afro-Asiatic phylum),包含北非,阿拉伯半岛及西亚周边地区共250种语言,其原始语言可追溯到公元前15000-9000年。这些语言共同的特征包括:固定高低调系统、咽擦音/ħ/以及显赫的用于表词义的辅音模式。 虽然语言学家和生物学家都假定单源发生说,但由于语言之间的频繁接触,我们当前的语言,即使是在同一语系内部,也很可能是多个不同语言交织发展而来的(如上文提到汉语的混合语序特征)。语言的多源说给谱系分类和类型学分类带来一些困难。对于前者来说,语言多源发生意味着对谱系分支树形态的认定问题;对于后者来说,语言类型学家在进行跨语言采样的过程中,有时候难以区分哪些特性是一组语言特有的,哪些特性是由语言接触而带来的相似性。在构建大规模语言样本库时,某些语言特征还很容易通过迁移或借用轻易地跨越语系、语族边界,从而被误认为是人类语言或某个语系言共有的特征或倾向(吴建明、金立鑫2017)。 4.2 语言和方言 一般认为互通性(mutual intelligibility)是区分语言和方言的标准。两种语言变体究竟在多大程度上互通才被称为方言?这个问题目前学界没有确切的定性和定量标准。比如,英语一半以上的词汇来自法语或拉丁语,但英语并不是法语的一个方言,而是日耳曼语族的一员;同样,罗马尼语(Romani)(吉普赛人的语言)大量借用所居地的词汇,和当地语言有一定的互通性,但也不是地方方言,其核心词汇以及屈折变化模式源自印度-雅利安语族(Indic languages)。此外,诸多非语言因素(如政治、文化、宗教等)常常把方言判定为语言。例如,在南斯拉夫战争之后,塞尔维亚-克罗地亚语(Serbo-Croatian)分裂为塞尔维亚语、克罗地亚语、波斯尼亚语和黑山语,但它们原本是一种语言。同样,印地语(Hindi)和乌尔都语(Urdu)由于分属两个主权国家,即印度和巴基斯坦,因此被一部分人称为两种语言。 就汉语而言,一般认为官话方言,吴方言、湘方言、客家方言、闽方言、粤方言和赣方言是汉语的七大方言,但这些方言之间大多不具备口语上的互通性。这是因为除了地理因素外,汉语方言还存在较大历史层次差异,即它们在不同程度上保留了古汉语在某个历史阶段的特征。王洪君(2009)认为闽方言是最早从上古汉语(周秦两汉时期)分支出去的,随后是吴、赣方言(两晋南北时期),之后是粤方言(晚唐五代时期),而湘方言和山西一些次方言是在宋代分支出去的。 由此可见,语言和方言的划分并不是泾渭分明,而互通性也不是唯一标准,这是谱系分类和类型学分类需要考虑的问题。 4.3 证据的选取 不管是原始语构拟,还是语言和方言的划分,一个最关键的因素是语言学证据的选取。在新近的研究中,语言学家发现核心词表中的词汇并不都享有一样的演变速度。斯瓦迪士的单词表中,“两个”、“谁”、“舌头”、“一个”、“死亡”等词汇在印欧语系中较为稳定,而“肮脏”、“转身”、“刺伤”等较多发生替代。与之类似,现代汉语中的“吃”在口语中也取代古汉语的“食”,而古汉语的“街”字则沿用至今。 除了词汇替代外,系统性的音变也可能是多次创新的产物,这就给谱系分类增加了难度。上文中我们提到吴语的浊声母是中古汉语的存留,而官话区的浊音清化则是一种系统性的创新。然而,有学者认为吴方言和闽方言共同经历了一次浊音声母变送气清声母的过程。此后,在北方汉语的影响下,吴方言重新产生了浊声母,而闽语只有部分字变成了浊声母,这部分字此后经历了第二次浊音清化,变成不送气清声母(陶寰2018)。同样,原始拉丁语发生系统性音变后,导致罗马各省的通俗拉丁语/h/不发音。当前大部分罗曼语继承了这一特点。如法语historique/istɔʀik/(cf.英语historic)。然而,这个过程不是简单的直系传承,而是借用和创新共同作用完成的:法语从德语和阿拉伯语借用了送气的/h/音,如hanche今读/'ãʃ/“臀部”(德语借词)和hammam今读/'amam/“土耳其浴”(阿拉伯语借词),但又发生了二次创新,再次脱落/h/。因此,法语/h/声母历时重构并不是一种简单的直进演化关系,而是一个复杂保留、借用和创新的过程。这些说明语言存在多次创新的可能性,而每一次系统性的创新也意味着对现有语言分支体系的潜在变革。 此外,语言之间并不是共享的词汇越多,它们的亲缘关系就越高,因为词汇是最可能被借用的语言项。相反,一些具有类型学意义的聚合结构或范式(如形态标记的聚合),只要在三个或三个以上的语言中出现(Campbell 2013:358),就有充分的理由作为语言分类或原始语构拟的证据。比如,在北日耳曼语中只有冰岛语存在四种格的形态变化(如指示代词分主格、宾格、与格和领属格);如果仅仅考察北日耳曼语,我们很可能认为这是一种自主创新,因为该分支里其他语言都没有这种变化。然而,在西日耳曼语支里,我们发现古德语和古英语有五种格,即主格、宾格、与格、领属格和工具格;古弗里斯语也有主格、宾格、与格和领属格四种格(现代德语有四种格,即主格、宾格、与格和领属格;现代英语有三种格,即主格、宾格、领属格;现代弗里斯语只有领属格)。由于现代德语和古弗里斯语存在和冰岛语同样的格范式,因而成为历史重构的关键证据。当然,除了格范式外,领属语和名词语序、宾语和动词语序、附置词和名词短语语序等,被认为是一些最具稳定性的类型学特征。这些是在词汇和语音规律之外,很有意义的与类型学相结合的谱系分类探索。 4.结语 本文分别讨论了语言学的两个重要的分类体系,即谱系分类和类型学分类。这两个分类体系都是对世界语言的范畴化,不同在于前者根据语言的谱系传承和亲缘关系,把语言划分为语系、语族或语支,并具体到语言或方言;后者对语言的音系、形态、句法、语义语用功能进行分类,并对各个类型进行具体化研究并挖掘共性规律。谱系分类和类型学分类是相互关联的,合理的谱系分类有助于类型学大规模的语言采样调查,避免高尔顿问题。类型学的研究成果则有助于谱系分类朝多元化证据发展。以往这两个领域各有侧重,作者借此机会,抛砖引玉,希望为今后的跨领域研究提供一些有用的参考。 参考文献 Campbell, L. 2013. Historical Linguistics. Edinburgh:Edinburgh University Press. Haspelmath,M.2010.Comparative concepts and descriptive categories in crosslinguistic studies.Language 86(3):663-687. Hock,H.H&B.D.Joseph.2009.Language History,Language Change,and Language Relationship:An Introduction to Historical and Comparative Linguistics.Berlin:Walter de Gruyter. Jin,Lixin(金立鑫).2019.A typological perspective on word order in Mandarin Chinese.Journal of PLA University of Foreign Languages(4):1-13.[2019,汉语语序的类型学特征.《解放军外国语学院学报》第4期:1-13.] Karlgren,B.1954.Compendium of Phonetics in Ancient and Archaic Chinese.Göteborg:Elanders Boktryckeri Aktiebolog. Sagart,L.,G.Jacques&Y.Lai 2019.Dated language phylogenies shed light on the ancestry of Sino-Tibetan.Proceedings of the National Academy of Sciences 116(21):10317-10322. Swadesh,M.1950.Salish internal relationships.International Journal of American Linguistics 16(4):157-167. Tao,Huan(陶寰).2018.The pronunciation of the Yun(云)and Xia(匣)initials in Wu and Min dialects and the devoicing of Middle Chinese voiced initials in Min dialects.Studies of the Chinese Language(3):335-350.[2018,吴闽语云匣母的读音和闽语全浊声母的清化.《中国语文》第3期:335-350.] Thurgood,G.&R.J.LaPolla.2003.The Sino-Tibetan Languages.New York:Psychology Press. Wang,Hongjun(王洪君).2009.A historical relation model of Chinese dialects with multiple perspectives of evolution,level and stratum.Dialect(3):204-218.[2009,兼顾演变、推平和层次的汉语方言历史关系模型.《方言》第3期:204-218.] Wu,Jianming.2019.The inventory structure of Person in the Chinese dialect of Puxian.Language and Linguistics 20(4):631-655. Wu,Jianming(吴建明)&Jin,Lixin(金立鑫).2017.Correlations in linguistic typology.Foreign Language Teaching and Research(5):710-718.[2017,语言类型学的“相关性”研究.《外语教学与研究》第5期:710-718.] Zhang,M.,S.Yan&W.Pan 2019.Phylogenetic evidence for Sino-Tibetan origin in northern China in the Late Neolithic.Nature 569(7754):112. (责任编辑:admin) |
- 上一篇:当代汉字应用热点问题回顾与思考
- 下一篇:批评话语研究的三个新动态