|
摘 要:从搭配的界定入手, 讨论语料库搭配研究的各种测量手段及存在的难题, 并探讨和评价中国学习者搭配分析的作用与意义。结论认为, 对搭配不同的定义方法, 反映了不同学科和领域观察和分析搭配的视角差异, 呈现出搭配研究的多元化特征;统计测量及自动处理无法取代研究者的判断和分析, 因为意义的产生与谈判并不纯粹遵从逻辑和概率。在外语学习与教学中, 如何将搭配融合于语言学习过程仍然需要更多的研究;处于固定与自由组合之间的各种变异性搭配使用, 是语言使用者及外语学习者体现语言创新能力的主要区域。 关键词:搭配的界定;搭配测量;学习者语料库;学习者搭配 作者简介: 李文中, 北京外国语大学中国外语与教育研究中心教授, 专职研究员, 博士, 博士生导师, 研究方向:语料库语言学、应用语言学。 基金: 国家社会科学基金项目“基于语料库的中国文化英语表述中外对比研究” (项目编号:13BYY019); 教育部人文社会科学重点研究基地资助项目 (项目编号:13JJD740005) 的部分研究成果。 1. 引言 搭配即语言使用中两个或两个以上词语在给定跨距内 (如Span=±5) 的重复同现, 反映了语言中“词语就像人一样结伴”的现象。语法分析中对搭配现象较早的关注大多与外语学习相关, 其焦点在于词语的组合对于意义表达、词汇记忆、语言产出的流利度与习语性 (Jespersen 1904;Hornby 1935) 。20世纪30年代, 前苏联学者针对短语学单位进行了深入的研究, 并把该单位在功能和结构上划分为“类词表达”和“类句表达”两种类型 (参见Cowie 1998a:3-8;Pawley 2007:10) 。20世纪50年代, 英国语言学家J.R.Firth把搭配这一概念引入到他的语言学意义语境理论中, 提出“由搭配而知意义”, 论述了搭配语境对词语意义的重要作用 (Firth 1957a, 1957b, 1957c) ;此后, Halliday (1966:158-9) 深入论述了词语作为语言学研究的一个重要层级;而Sinclair (1966:412;Sinclair et al.1970) 则通过自己的研究实践, 确立了搭配测量和分析过程中一系列重要术语和方法。20世纪80年代以后, 随着计算机技术的发展, 语料库搭配研究在词典编纂、语言分析、学习者语言研究等领域得到长足发展, 尤其是Sinclair从搭配研究入手, 提出词语法 (lexical grammar) 理论, 认为在语言使用中, 词语组合序列才是意义分析的起点和中心, 而具有独立意义的单个词语只是语言的边缘性现象, 并提出了“习语原则”与“开放选择原则”两大语言组织原则, 还为此提出并实施了一系列分析原则和方法 (Sinclair 1991, 2000, 2001, 2004a, 2004b) 。语料库语言学的兴起, 结合语料库证据的搭配研究显得更有说服力 (方子纯2013:45) 。由此, 语料库搭配研究成为多名学者的关注焦点 (如Stubbs 2001;Hoey 2005;Tognini-Bonelli2001;Hunston&Francis 2000) 。在国内, 外语界语料库搭配研究始于20世纪90年代后期对学习者语言的观察和分析, 着重从学习者书面语或口头语文本中分析词语组合或搭配的使用特征, 主要视角可分为两种, 一是从交际策略视角研究学习者词语组合的个性特征 (李文中1999) , 另一个就是从对比中介语分析视角分析学习者的动词搭配行为 (卫乃兴2002;濮建忠2003) 。之后的研究基本沿袭了对比中介语分析的研究视角, 通过对比观察和分析中国英语学习者搭配使用困难, 试图从母语迁移及学习不足等方面归因错误, 从而提出教学补偿。该范式由于其自身理论的缺陷, 以及国际英语使用语境的变化, 开始受到质疑和反思 (李文中2009) 。本文从搭配的界定入手, 讨论语料库搭配研究的各种测量手段及存在的难题, 并探讨和评价中国学习者搭配分析的作用与意义。 2. 搭配的界定及分析难题 虽然搭配作为一种语言现象, 已引起了语言学界普遍的关注, 但学者们对搭配的观点却是同中见异, 众说纷纭。这一点从众多学者对搭配的不同定义上就可以看出来, 不同的定义反映出学者的迥异的观察视角和研究取向。Seretan (2011) 在她的著作附录中列举了从1957年 (Firth) 到2008年五十年间, 共二十位学者对搭配的定义, 这还不包括与所列出的学者具有相似研究理念的其他学者。在这些定义中, 有十五位学者指出了搭配是一种词语“组合” (combination) 或“同现” (co-occurrence) , 说明“同现”是搭配的核心特征, 有十一位学者提出了搭配的结构特征或语义特征, 表明大多数学者基本共识, 即搭配不仅是一种词语的同现, 还具有语法结构及语义属性的识别特征。但是, 如何看待这些特征以及这些特征之间的关系, 学者们的观点分歧较大。为了梳理搭配的定义, 更清晰地辨别其中的异同, 有学者对搭配研究概括了三种分类方法, 即词语构成方法、语义方法、及结构方法 (Gitsaki 1996) 。这实际上是把词语搭配序列分析、语义分析、及结构分析看成了三个支点, 并从中审视研究者的出发点和研究聚焦。比如词语构成方法强调词语的同现与复现, 主张词语序列与搭配结构并不存在截然分明的界线, 通过词语看结构;与此相比, 结构方法也强调词语、语法及语义相互依存, 但其出发点是确立搭配的结构型式, 再通过结构去看词语。而语义方法试图通过语义特征分析, 预测搭配词 (Gitsaki 1996:160) 。这种分类方法从搭配定义出发, 对不同方法的研究思想和实践关照不够, 且划分互有交叉, 缺乏依据, 如把Sinclair与Renouf划分为结构方法, 显得依据不足。Evert (2004) 把搭配界定归纳为二种方法, 分别为“位置分布型方法” (positional distribution approach) 及“内涵型方法” (intensional approach) , 前者强调某一具体文本中复现的词语同现, 包括词语同现的频数及词语联系的统计值, 而后者把搭配界定为是一种词语组合, 其语义或句法关系不能由其内部组成元素预测, 则该词语组合须列入词符表。Evert认为, 后者基于某个语言学理论的定量分析更清晰, 更有意义;在实践上, 位置同现往往包括了各种混杂的结构关系, 至少在给定的跨距内或句子内就有多种同现的理据。实际上, 这种观点仅仅基于对搭配词对的观察和测量, 无视搭配分析过程中扩展语境对搭配结构和语义的消岐, 也忽略了Sinclair的“扩展意义单位分析”的研究实践。也有学者从搭配的产生机制来解释搭配与短语单位的关系, 认为不是搭配引起了短语单位, 而是更大的短语单位促生了搭配 (Barnbrook, Mason&Krishnamurthy 2013:165) 。Seretan (2011) 基本上沿袭了Evert的思想, 把搭配定义分为“基于统计的方法”与“基于语法的方法”, 概括起来就是, 基于统计的方法认为搭配中的词语关联具有统计学意义, 且词语互相预期 (选择) ;搭配关系不平衡, 可区分为上行搭配与下行搭配1;而基于语法的方法强调句法结构的先决性及良好性, 同时也观察词语同现与复现。 正如Sinclair所言, 意义与结构不可分割, 抛开意义分析进行纯粹的词语同现统计, 或者孤立地进行语法分析, 都不足以区分和解释同现序列的意义关系。如以下短信段子: (1) 冬天:能穿多少穿多少;夏天:能穿多少穿多少。 (2) 地铁里听到一个女孩儿大概是给男朋友打电话:“我已经到西直门了, 你快出来往地铁站走。如果你到了, 我还没到, 你就等着吧。如果我到了, 你还没到, 你就等着吧!” 在第 (1) 例中, “多少”作为同现序列出现4次, 但该序列在前句和后句呈现出不同的结构关系和意义关系, 前者是习语, 表示数量;后者是修饰结构。第 (2) 例中“你就等着吧”同样是一个复现的同现序列, 但其在前句是一个可分析的主谓结构, 表达字面意义的请求, 而在后句就是一个不可进一步分析的习语序列, 表示语用的警告和威胁。以上两例仅依据同现和复现的标准就会遇到很大的难题。基于语法的方法强调句法结构的先决性和结构的良好性, 把搭配序列看成是一个句法或语义单位, 但很难解释搭配中的词语可交替性限制, 某些搭配词从语义视角是可以交替使用的, 但从搭配视角却不交替使用 (Sinclair 2004b:285) ;一些词语序列表现出纯粹的搭配行为, 不能由语法直接解释。尽管各种研究搭配的路径和视角不一, 但对搭配的基本属性还是存在一定的共识, 如搭配是预制性短语, 是任意的、不可预测的;搭配是复现的;搭配关系具有复杂性, 表现在不对称、不平衡、方向性和序列性等 (Seretan 2011:15) 。 为解决上述难题, Stefanowitsch and Gries (2003:214) 试图把意义单位理论与构式语法、认知语法等结合起来, 提出搭配构式 (collostruction) 分析方法, 期望该方法“既对语言结构敏感, 也对各个层面上产生的具体构式敏感”;在这种构式中, “受某一具体结构吸引的词位 (lexemes) 称作该结构的搭配位 (collexemes) ;反之, 与某一具体词位相关联的结构称作搭配构 (collostruct) ;搭配位与搭配构的结合称作搭配构式” (Seretan 2011:215) 。与以往结构分析不同的是, 搭配构式在分析中先观察同现词语结构, 这种词语结构或搭配构不是抽象的语法范畴, 而是具体的词语序列, 通过分析搭配位上的搭配词集来获取整个序列的意义, 如上述两位学者所举的实例“[N]waiting to happen”中, N表示搭配位, 而后跟的“waiting to happen”则是搭配构, 通过该搭配构与搭配位上的词位共现, 测量其联系强度, 从而观察整个搭配构式的意义和态度, 如他们发现经常出现的词位大多是“几乎肯定要发生或在当前时间迹象明显的含有消极意义的事件” (Seretan 2011:215) 。搭配构式可作为意义单位分析的一个补充, 以构式为观测节点, 再去看与该构式共现的搭配词, 丰富了搭配研究的视野, 但搭配构式分析却不能代替扩展单位意义分析。 3. 搭配的测量与作用 既然搭配是一种复现特征, 而同现的词语又是互相期望或共选的, 那么通过统计和检验测量搭配的强度无疑是搭配分析初始阶段重要的依据。在一个语料库中可以测量出任意两个词的原始频数, 并计算其同现的期望概率, 再与实际观测的同现概率相比, 得出该搭配的强度值。搭配的强度测量旨在确定, 在一个节点词的给定跨距内, 某一搭配词的同现/复现频率是否具有统计学意义 (Z, T) , 这个主要通过对比实际观测的频数与期望频数, 计算该搭配词与节点词的搭配力, 一般使用Z、T、MI、MI3等检验方法。这种测量存在几个主要难题:1) 无法表示搭配的序列信息, 即到底是哪一个词更能预测另一个词的同现, 其搭配的顺序如何;2) 不够精细, 缺乏词性信息;3) 缺乏搭配词在跨距内的分布信息, 仅靠同现频数是不够的。为说明这一问题, 我们以of course为例, 使用CROWN语料库, 分别以其中一个词为节点词, 对比四种统计检验结果, 如表1: 表1.四种统计检验结果对比 (语料库总形符=1006990)  表1显示, 不论以哪个词为节点词, 并不影响其测量结果, 除Z值稍有差异外, 其他统计值都是一样的, 说明以上四种统计检验不能表明搭配内部互选关系的不平衡性, 即搭配中的某一个词对另一个更具预测性;此外, 上述统计没有考虑搭配词的位置分布。搭配词在跨距内的位置分布能帮助我们确定搭配词的有效性。如果一个搭配词wi在跨距内各个位置j上频数非常接近, 即该搭配词在跨距内10个位置 (假设跨距设定为5+5-) 分布均匀, 那么该词不是节点词真正的搭配词。如图1是“大学英语学习者语料库 (COLEC) ”中节点词knowledge的搭配词learn和help的分布统计, 其中learn在左二的位置 (N-2) 呈现峰态, 而在其他位置的分布趋于平坦 (李文中1999:117) 。这个分布至少有两个信息: (1) learn应该是一个真正的搭配词; (2) 其主要位置处于节点词左二的位置。与learn相比, help在各个位置上的分布比较均匀, 没有出现峰态, 可见help虽然频数也很大, 但却不是节点词的真正搭配词。表达搭配词在跨距内各个位置的分布需要一个测量值, 如计算搭配词在跨距内的分布均值, 然后再求出方差, 用来表示分布的均匀度, 方差值越小, 则表示搭配词的分布越均匀, 其作为搭配词的可能性越小。 也有学者提出利用搭配词的词性信息对搭配进行精细统计和筛选 (Smadja 1994) 。由于英语词语的词性是可变的, 同一词形可能具有不同的词性, 而节点词只跟该词的某一词性搭配。所以分别计算某一词性与节点词的搭配是合适的。由此, 针对某一节点词NW, 我们可以首先统计NW的搭配词表W, 再分别计算词表中每一个搭配词的词性频数wi, 再计算该词性在跨距内各个位置的均值和方差, 就可以得到更精细的结果。如上述knowledge的搭配词learn的方差Ulearn=1177.34, 而Uhelp=139.6, 二者相差非常大。这样一来, 搭配词的计算由三个条件控制:1) 搭配力度, 即传统的Z、T值计算;2) 跨距U0, 一般为5+5=10, 即跨距>=U0;3) 某一词性在跨距内的分布方差。把以上三个条件结合在一起, 可对搭配进行筛选统计2。以上思路只能计算节点词与搭配词的两两搭配, 对两词以上的序列尚不能准确测算。此外, 这种搭配计算忽略了搭配的方向性和序列性。近几年Gries (2013) 提出了delta P的计算方法, 分别测量两个词的预测强度3。 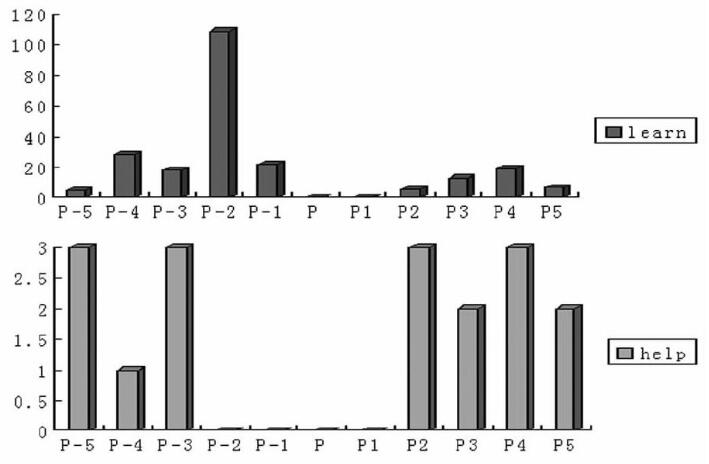 图1.knowledge搭配词 (learn, help) 的位置分布对比 (COLEC) 无论搭配的测量算法如何改进, 其目的无非是1) 为进一步的搭配分析提供统计依据;2) 为搭配的自动识别和提取提供可行路径。在实际的搭配意义分析中, 统计只起到辅助作用, 过份依赖统计效果只会适得其反 (李文中2016:41-42) 。 4. 搭配与学习者语言分析 搭配研究与外语学习具有天然的联系。现代外语教学对搭配的关注可追溯到20世纪初Jespersen的研究。Jespersen (1904) 在他的《如何教外语》一书中, 较早地关注到了搭配对外语学习和教学的作用, 他虽然没有明确使用“搭配”这一术语, 但多处讨论到“词语组合” (combination (s) ) 对外语教学的重要意义, 尤其强调词语组合学习对词汇记忆、理解以及使用的重要价值。之后, 1927年, 在日本“英语教学研究院” (IRET) 任职的英国学者Harold E.Palmer启动了一项课题, 为英语教学编制搭配词表, 1931年, 同在日本任教的英国学者Albert Sydney Hornby加入Palmer的团队, 并完成了6000多词的搭配词表 (参见Cowie 1998b) ;1935年, Hornby (1935) 发表了《搭配研究第二份中期报告》, 成为外语教学研究中搭配研究的“地标性成果” (Cowie2012:389) , 该报告排除了“类句”的整句表达, 而聚焦那些在单句中“类词”的组成成分, 并进一步分为“名词组合”与“动词组合” (Cowie 2012:389) 。在学习者语言分析中, Halliday (1966:160) 也较早地注意到了搭配在学习者语言能力中的关键性作用, 提出大量的学习者错误都可以在搭配层面得到解释。学者们认为, 学习者掌握一定数量的习语及预制性词块, 语言处理时间更短, 也有助于提高语言输出的“地道性”和流利程度 (Pawley and Syder 1983) 。在当代外语教学研究中, 学者们较早关注的是, 搭配或词语组合在词汇学习及交际能力发展中的积极作用 (如Bolinger 1976;Nattinger&De Carrico 1992;Cowie 1978;Gitsaki 1996) , 主要观点是 (李文中1999:97) , 1) 搭配是一种特殊的词汇学习, 学习者通过词块学习词汇 (Bolinger 1976) ;2) 学习者搭配知识的增长有助于提高他 (她) 们口语、听力及阅读速度;3) 搭配是学习困难的根源之一, 同时对搭配的掌握也标志着能力的进步;4) 词语组合在交际能力发展上起到关键作用;5) 语言预制块及常例化语式对语言习得及使用非常重要 (Nattinger&De Carrico 1992) 。正如Cowie (2012:389) 所言, 对“各种类型的词语组合的充分关注, 已经在我们的语言学习与教学观念中占据支配地位。...更加重要的是, 我们看到搭配与习语已经在学习者词典的设计思想中占据中心地位。”值得注意的是, 判断学习者对搭配的掌握, 以及其语言流利和地道的标准, 大多是以英语本族人的搭配使用为规范或标准, 观察学习者搭配是否与本族人一致。 随着学习者语料库的开发和应用, 学者们开始把语料库与学习者语言分析结合起来。为此, 比利时鲁汶大学的Granger (1996, 2003) 组织创建了国际学习者英语语料库, 并提出了“对比中介语分析 (CIA) ”框架, 结合中介语分析及错误分析理论与语料库方法, 通过多个维度对比学习者语言与英语本族语, 试图获得学习者典型困难, 以求在补偿式教学中得到解决。随后, 各国外语英语学习研究者纷纷从该范式中获取灵感, 利用自建的学习者语料库进行各种错误分析。在中国, “中国学习者英语语料库 (CLEC) ”在20世纪90年代末完成, 随后的专业英语学习者口笔语语料库 (SWECCL) 也相继建成, 基于学习者语料库的搭配分析如火如荼, 几成中国外语教学领域语料库研究主流方法4。综观中国学习者语料库搭配分析, 主要呈现以下特征:1) 在理论上多受Granger的CIA理论影响, 利用现有的学习者语料库或自建语料库, 通过与本族语语料库或者本族语学习者语料库, 分析中国学习者的搭配困难;2) 在对比中重点观察学习者搭配使用与本族语料的差异;大多数研究都注意到中国学习者在使用搭配时, 所选择的搭配词显得自由而多样 (李文中1999) ;而本族人在同类的搭配中选择的搭配词具有更大的限制性;3) 在结果解释中, 一般把学习者搭配特征归类为“多用”、“少用”及“误用”, 其主要原因是母语的干扰、目的语资源不足、以及学习的不足等;4) 对难题的解决, 一般主张通过补偿教学提升学生对搭配的使用意识, 提高搭配使用的准确性和地道性。 相对传统的语法错误分析而言, 基于学习者语料库的搭配分析是一种更深层次的研究。但是与语法使用相比, 搭配使用更复杂。搭配高度依赖社会文化, 对使用语境也高度敏感。换言之, 学习者使用的词语组合或搭配, 与他 (她) 们的社会文化认知、生活经验、以及日常活动紧密相联, 如learn knowledge, enter the society这种搭配反映了学习者自身生活经验的特异性, 虽少见于本族语语料库, 但未尝就是错误搭配。此外, 中介语理论已经摒弃了错误分析的理念, 既把学习者语言特征视作偏离本族语标准的错误, 而试图通过学习者视角, 肯定学习者语言的体系性及合法性, CIA重拾错误分析的套路, 在方法上是先进的, 在理念上是落后的;最后, 由于通用英语 (English as a Lingua Franca) 理论范式的挑战, 学习者语料库搭配分析需要更多元的视角及更开放的态度去审视学习者的搭配使用 (参见李文中2009) 。 5. 结论 正如Sinclair (2000) 所言, 在语言学及应用语言学研究中, 短语学研究已占据“中心地位”, 而搭配分析则是短语学研究的核心问题。对搭配不同的定义方法, 反映了不同学科和领域观察和分析搭配的视角差异, 呈现出搭配研究的多元化特征, 同时不同的理念和方法也呈现出竞争态势。本文只聚焦了语料库搭配研究的主要问题, 限于篇幅, 尚未涉及心理语言学、认知语言学、二语习得、计算语言学等领域对搭配的研究及成果。搭配的测量与提取将随着计算机技术与语言学理念的发展, 为研究者提供更好的数据形态, 但统计测量及自动处理无法取代研究者的判断和分析, 因为意义的产生与谈判并不纯粹遵从逻辑和概率。在外语学习与教学中, 搭配的重要性已得到充分的关注, 但如何将搭配融合于语言学习过程仍然需要更多的研究。此外, 处于固定与自由组合之间的各种变异性搭配使用, 才是语言惯例与创新的基本界面, 也是使用者及外语学习者体现语言创新能力的主要区域。 参考文献 [1]Barnbrook, G., Mason, O., &Krishnamurthy, R.Collocation—Applications and Implications[M].Palgrave Macmillan, 2013. [2]Bolinger, D.Meaning and memory[J].Forum Linguisticum, 1976 (1) :1-14. [3]Cowie, A.P.Introduction[A].In A.P.Cowie (ed.) .Phraseology:Theory, Analysis and Application[C].Oxford:Clarendon Press, 1998a:1-22. [4]Cowie, A.P.AS Hornby:A centenary tribute[A].Euralex’98:proceedings I-II:papers submitted to the Eighth EURALEX International Congress on Lexicography in Liège, 1998b:3-16. [5]Cowie, A.P.IJL:Dictionaries, language learning and phraseology[J].International Journal of Lexicography, 2012 (4) :386-92. [6]Evert S.The Statistics of Word Co-Occurrences:Word Pairs and Collocations[D].Stuttgart:University of Stuttgart, 2004. [7]Firth, J.R.Papers in Linguistics 1934-1951[M].Oxford:Oxford University Press, 1957a. [8]Firth, J.R.A synopsis of linguistic theory, 1930-55[A].In J.R.Firth (ed.) .Selected papers of J.R.Firth, 1952-59[C].Indiana University Press, 1968:168-205. [9]Firth, J.R.Ethnographic analysis and language with reference to malinowski’s views[A].In J.R.Firth (ed.) An Evaluation of the Work of Bronislaw Malinowski[C].London:Routledge&Kegan Paul, 1957b:93-118. [10]Granger, S.From CA to CIA and back:An integrated approach to computerized Bilingual and Learner Corpora[A].In K.Aijmer, B.Altenberg&M.Johansson. (eds.) .Language in Contrast:Text-based Cross-Linguistics Studies[C].Lund:Lund University Press, 1996:37-51. [11]Granger, S.The international corpus of learner English:A new resource for foreign language learning and teaching and second language acquisition research[J].TESOL Quarterly, 2003 (3) :538-46. [12]Gitsaki, C.The Development of ESL Collocational Knowledge[D].Queensland:University of Queensland, 1996. [13]Halliday, M.A.K.Lexis as a linguistic level[A].In C.E.Bazell et al. (eds.) .In Memory of J.R.Firth[C].London:Longmans, 1966:148-162. [14] Halliday, M.A.K., &Hasan, R.Cohesion in English[M].London:Longman, 1976. [15]Hoey, M.Lexical Priming:A New Theory of Words and Language[M].London:Routledge, 2005. [16]Hornby, A.S.Second Interim Report on English Collocations[R].Report submitted to the Tenth Annual Conference on English Teaching, Tokyo, 1935. [17]Hunston, S., &Francis, G.Pattern Grammar:A Corpus-Driven Approach to the Lexical[M].Amsterdam:John Benjamins, 2000. [18]Jespersen, O.How to Teach a Foreign Language[M].Translated from the Danish original by Sohia Yhlen-Olsen Bertelsen.London:George Allen&Unwin Ltd., 1904. [19]Nattinger, J., &De Carrico, J.Lexical Phrases and Language Teaching[M].Oxford:OUP, 1992. [20]Pawley, A.&F.Syder.Two puzzles for linguistic theory:Nativelike selection and nativelike fluency[A].In J.Richards&R.Schmidt (eds.) .Language and Communication[C].London:Longman, 1983:191-225. [21]Pawley, A.Developments in the study of formulaic language since 1970:A personal view[A].In P.Skandera. (ed.) .Phraseology and Culture[C].Berlin/New York:Mouton de Gruyter, 2007:3-48. [22]Seretan, V.Syntax-based Collocation Extraction (Vol.44) [M].Springer, 2011. [23]Sinclair, J.Mc H.Beginning the study of lexis[A].In C.E.Bazell et al. (eds.) .In Memory of J.R.Firth[C].London:Longmans, 1966:410-430. [24]Sinclair, J., Jones, S.&Daley, R.The OSTI Report[R].1970.Reprinted as J.Mc H.Sinclair, S.Jones, &R.Daley.English Collocation Studies:The OSTI Report[M].R.Krishnamurthy. (ed.) .London:Continuum, 2004. [25] Sinclair, J.Mc H.Corpus, Concordance, Collocation[M].Oxford:OUP, 1991. [26]Sinclair, J.Mc H.Lexical grammar[J].Darbai ir Dienos, 2000 (24) :191-203. [27]Sinclair, J.Mc H.Book review of LGSWE[J].International Journal of Corpus Linguistics, 2001 (2) :339-359. [28]Sinclair, J.Mc H.Trust the Text:Language, Corpus and Discourse[M].London and New York:Routledge, 2004a. [29]Sinclair, J.Mc H.New evidence, new priorities, new attitudes[A].In J.Mc H.Sinclair (ed.) .How to Use Corpora in Language Teaching[C].Amsterdam:John Benjamins Publishing Company, 2004b:271-299. [30]Smadja, F.Retrieving collocations from text:Xtract[A].In S.Armstrong (ed.) .Using Large Corpora[C].Cambridge:Association for Computational Linguistics, 1994:143-178. [31]Stefanowitsch, A.&Gries, S.Th.Collostructions:Investigating the interaction of words and constructions[J].International Journal of Corpus Linguistics, 2003 (2) :209-43. [32]Stubbs, M.Words and Phrases:Corpus Studies of Lexical Semantics[M].Oxford:Blackwell Publishers Ltd, 2001. [33]Tognini-Bonelli, E.Corpus Linguistics at Work[M].Amsterdam/Philadelphia:John Benjamins Publishing Company, 2001. [34]方子纯.词汇意义的百科性与搭配潜势[J].外语教学, 2013 (3) :41-45. [35]李文中.CIA方法述评[J].外语电化教学, 2009 (3) :13-7. [36] 李文中.An Analysis of the Lexical Words&Word Combinations in the College Learner English Corpus[D].Shanghai:Shanghai Jiao Tong University, 1999. [37]李文中.语料库标记与标注:以中国英语语料库为例[J].外语教学与研究, 2012 (3) :336-345. [38]李文中.“新弗斯语料库语言学”考辩[J].外国语, 2016 (2) :38-46. [39]濮建忠.学习者动词行为:类联接、搭配及词块[M].开封:河南大学出版社, 2003. [40]卫乃兴.词语搭配的界定与研究体系[M].上海:上海交通大学出版社, 2002. 注释 1 Sinclair (1991) 提出, 当节点词频数小于搭配词频数, 称作上行搭配, 反之, 则称作下行搭配。 2 方差的计算步骤:1) 先求出搭配词在各个位置上的分布均值;2) 搭配词在每个位置上的实际频数减去均值并平方;3) 计算出搭配词的平方均值。 3 Gries使用了一个简单的公式, 如计算第二个词对第一个词的预测强度, 则公式为:delta P=a/ (a+b) -c/ (c+d) ;而计算第一个词对第二个词的预测强度, 则公式为:delta P=a/ (a+c) -c/ (b+d) (参见表1:列联表) 。 4 通过对中国知网的查询统计, 2000年以来基于语料库的学习者搭配分析达100余篇, 且多见于硕、博士论文, 由于篇数多, 不再一一详举。 (责任编辑:admin) |