|
2 评测任务 本节介绍了目前否定和不确定信息抽取研究涉及的三个子任务:线索词识别、覆盖域识别和聚焦点识别,以及任务评测指标。 计算自然语言学会议CoNLL’2010【2】针对不确定信息抽取研究提出了两个子任务[4]:线索词识别和覆盖域识别。在该评测中,线索词识别任务仅仅要求判断句子中是否包含不确定信息,而未将识别线索词作为目标,目前大多数研究通常会给出线索词识别的性能;覆盖域识别任务要求根据前一任务中识别的线索词,判断该句子内部表示不确定含义的片段。Blanco等[18]发现否定覆盖域中的内容在很多情况下可以再进一步分为事实内容和否定内容,该区分对更细粒度的文本语义理解具有重要意义。基于此,Blanco等提出了面向否定信息的聚焦点识别任务。该任务的主要目标是,在线索词的覆盖域中,识别其针对或强调的内容。Blanco等还基于PropBank语料库[19]标注了聚焦点识别语料。 以上提到的三个子任务具有不同侧重点:线索词作为一种语义标记【3】,其作用是标识出句子中包含的否定或不确定语义;覆盖域则划定了否定或不确定语义延伸的范围,重点在于指示出线索词管辖的片段;而聚焦点则是对否定或不确定内容更细粒度的表示,是覆盖域中被强调的部分。现有研究通常面向否定或不确定信息,针对其中一个或若干子任务开展研究工作。 目前通常使用两类指标来衡量否定与不确定信息抽取系统的性能:(1)正确率(Accuracy)。正确率以句子为基本单位,要求系统结果与正确答案严格匹配,该指标反映了系统判断出正确结果的能力;(2)准确率(Precision)、召回率(Recall)和 F 值。该指标通常以进行判别的实例为基本单位,反映了系统能够正确判断给定句子中是否包含否定或不确定信息的能力。 3 语料资源 2008年BioScope语料库出现之前,大多数研究通常采用人工或半自动方法收集否定或不确定信息语料,例如,Medlock等[20]以线索词为特征,从生物医学文献中半自动获取包含不确定信息的训练样本。常用的否定与不确定信息抽取语料有:(1)BioScope生物医学语料库。该语料库标注了否定和不确定线索词及其覆盖域;(2)维基百科语料。该语料利用维基百科中缺乏事实证明的描述文本(Weasels)构建语料。 3.1 BioScope语料库 为体现生物医学文献中语言的异构性,Bio-Scope语料库[11]包含了四种不同来源的语料:GE-NIA 语料库[21]中的文本摘要语料、五篇果蝇功能基因组文献的全文、四篇英国医学委员会(BMC)生物信息学网站的开源文章以及1954篇放射学临床报告。其中,GENIA语料库是一个生物医学文献集合,BioScope语料库包含了其中的1999条联机医学文献分析和检索系统的摘要,主题为“人”、“血细胞”和“副本因子”。标注者手工针对 BioScope语料库中14541个句子标注了否定和不确定线索词及其覆盖域。BioScope语料库根 据语料类型 不 同 分为三个子语料库,分别为摘要(Abstract)语料库、全文(Full Paper)语料库和临床记录(Clinical Report)语料库,详细统计信息如表1所示。 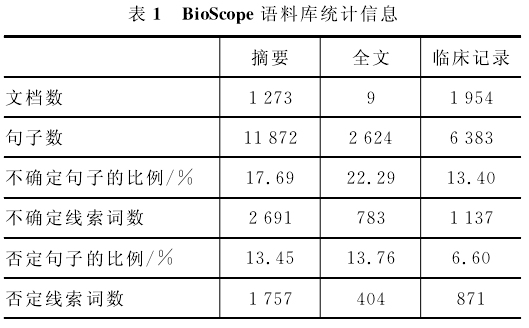 CoNLL’2010评测在BioScope语料库的基础上构建了评测任务的测试数据集,该语料集合增加了1篇随机从2009年10月BMC生物信息学专刊上获取的论文全文和五篇GENIA语料库的论文全文,全文语料总数为15篇,摘要语料和临床记录语料则与BioScope语料库一致。此外,评测机构还提供了未标注的150篇PubMed Central全文,这部分数据与标注数据一样进行了预处理工作,以此作为领域内的数据样本,供评测者使用。 (责任编辑:admin) |